Ten Hours of Static Gets Five Copyright Notices
Sebastian Tomczak blogs about technology and sound, and has a YouTube channel. In 2015, Tomczak uploaded a ten-hour video of white noise. Colloquially, white noise is persistent background noise that can be soothing or that you don’t even notice after a while. More technically, white noise is many frequencies played at equal intensity. In Tomczak’s video, that amounted to ten hours of, basically, static.
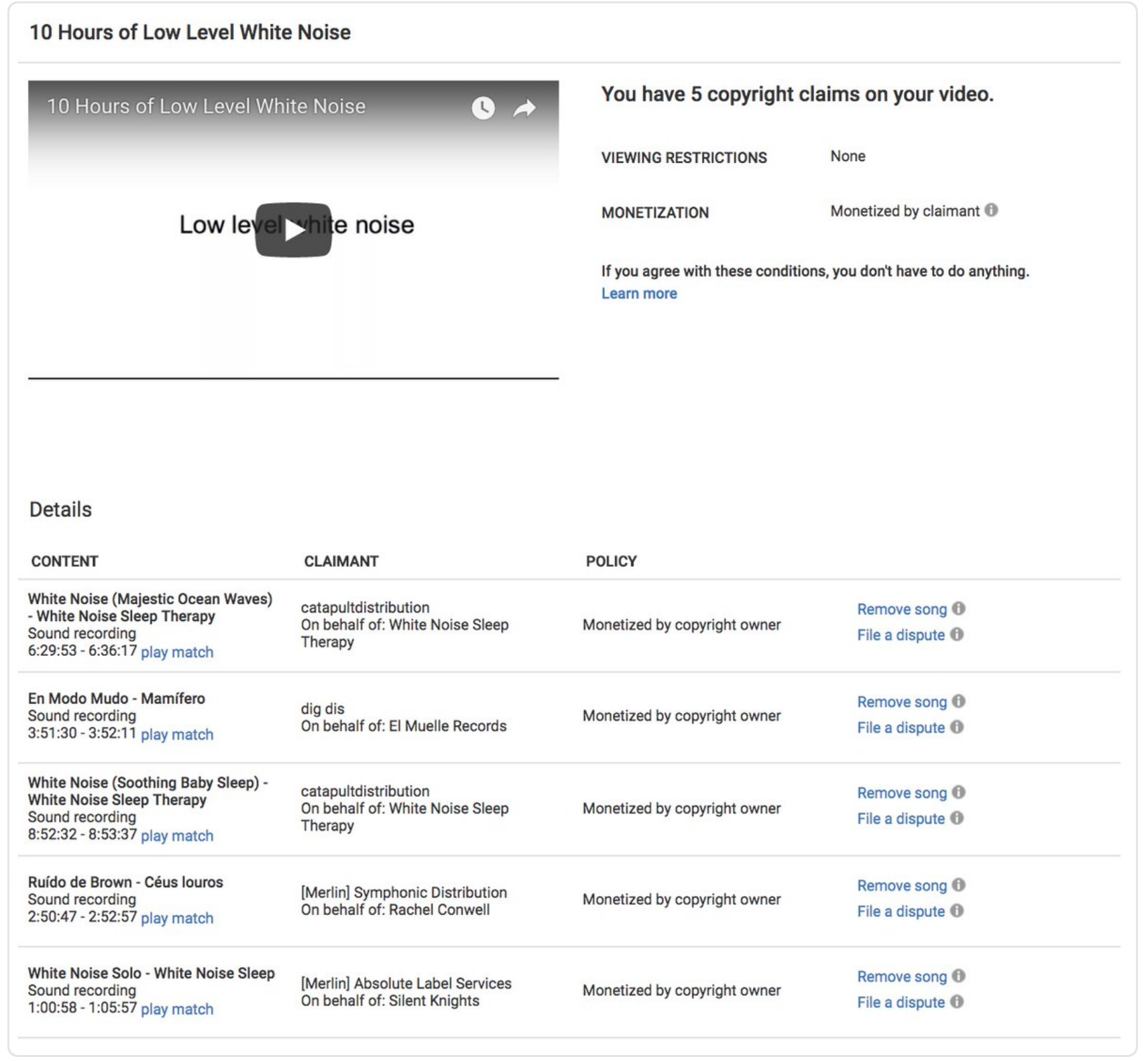
In the beginning of 2018, as a result of YouTube’s Content ID system, a series of copyright claims were made against Tomczak’s video. Five different claims were filed on sound that Tomczak created himself. Although the claimants didn’t force Tomczak’s video to be taken down they all opted to monetize it instead. In other words, ads on the ten-hour video would now generate revenue for those claiming copyright on the static.
Normally, getting out of this arrangement would have required Tomczak to go through the lengthy counter-notification process, but Google decided to drop the claims. Tomczak believes it’s because of the publicity his story got. But hoping your takedown goes viral or using the intimidating counter-notification system is not a workable way to get around a takedown notice.
YouTube’s Content ID system works by having people upload their content into a database maintained by YouTube. New uploads are compared to what’s in the database and when the algorithm detects a match, copyright holders are informed. They can then make a claim, forcing it to be taken down, or they can simply opt to make money from ads put on the video.
And so it is that an automated filter matched part of ten hours of white noise to, in one case, two different other white noise videos owned by the same company and resulted in Tomczak getting copyright notices.
Copyright bots like Content ID are tools and, like any tool, can be easily abused. First of all, they can match content but can’t tell the difference between infringement and fair use. And, as what happened in this case, match similar-sounding general noise. These mistakes don’t make the bots great at protecting free speech.
Some lobbyists have advocated for these kinds of bots to be required for platforms hosting third-party content. Beyond the threat to speech, this would be a huge and expensive hurdle for new platforms trying to get off the ground. And, as we can see from this example, it doesn’t work properly without a lot of oversight.