Measuring the Progress of AI Research¶
This pilot project collects problems and metrics/datasets from the AI research literature, and tracks progress on them.
You can use this Notebook to see how things are progressing in specific subfields or AI/ML as a whole, as a place to report new results you've obtained, as a place to look for problems that might benefit from having new datasets/metrics designed for them, or as a source to build on for data science projects.
At EFF, we're ultimately most interested in how this data can influence our understanding of the likely implications of AI. To begin with, we're focused on gathering it.
Original authors: Peter Eckersley and Yomna Nasser at EFF. Contact: ai-metrics@eff.org.
With contributions from: Yann Bayle, Owain Evans, Gennie Gebhart and Dustin Schwenk.
Inspired by and merging data from:
- Rodrigo Benenson's "Who is the Best at X / Are we there yet?" collating machine vision datasets & progress
- Jack Clark and Miles Brundage's collection of AI progress measurements
- Sarah Constantin's Performance Trends in AI
- Katja Grace's Algorithmic Progress in Six Domains
- The Swedish Computer Chess Association's History of Computer Chess performance
- Gabriel Synnaeve's WER are We collation of speech recognition performance data
- Qi Wu et al.'s Visual Question Answering: A survey of Methods and Datasets
- Eric Yuan's Comparison of Machine Reading Comprehension Datasets
Thanks to many others for valuable conversations, suggestions and corrections, including: Dario Amodei, James Bradbury, Miles Brundage, Mark Burdett, Breandan Considine, Owen Cotton-Barrett, Marc Bellemare, Will Dabny, Eric Drexler, Otavio Good, Katja Grace, Hado van Hasselt, Anselm Levskaya, Clare Lyle, Toby Ord, Michael Page, Maithra Raghu, Anders Sandberg, Laura Schatzkin, Daisy Stanton, Gabriel Synnaeve, Stacey Svetlichnaya, Helen Toner, and Jason Weston. EFF's work on this project has been supported by the Open Philanthropy Project.
Table of Contents¶
- Taxonomy
- Source code for defining and importing data
Problems, Metrics and Datasets
- Game Playing
- Vision and image modelling
- Written Language
- Spoken Language
- Music Information Retrieval
Learning to Learn Better
- Safety and Security
- Transparency, Explainability & Interpretability
- Fairness and Debiasing
- Privacy Problems
Taxonomy¶
It collates data with the following structure:
problem
\ \
\ metrics - measures
\
- subproblems
\
metrics
\
measure[ment]sProblems describe the ability to learn an important category of task.
Metrics should ideally be formulated in the form "software is able to learn to do X given training data of type Y". In some cases X is the interesting part, but sometimes also Y.
Measurements are the score that a specific instance of a specific algorithm was able to get on a Metric.
problems are tagged with attributes: eg, vision, abstract-games, language, world-modelling, safety
Some of these are about performance relative to humans (which is of course a very arbitrary standard, but one we're familiar with)
- agi -- most capable humans can do this, so AGIs can do this (note it's conceivable that an agent might pass the Turing test before all of these are won)
- super -- the very best humans can do this, or human organisations can do this
- verysuper -- neither humans nor human orgs can presently do this
problems can have "subproblems", including simpler cases and preconditions for solving the problem in general
a "metric" is one way of measuring progress on a problem, commonly associated with a test dataset. There will often be several metrics for a given problem, but in some cases we'll start out with zero metrics and will need to start proposing some...
a measure[ment] is a score on a given metric, by a particular codebase/team/project, at a particular time
The present state of the actual taxonomy is at the bottom of this notebook.
Source Code¶
- Code implementing the taxonomy of Problems and subproblems, Metrics and Measurements is defined in a free-standing Python file, taxonomy.py. scales.py contains definitions of various unit systems used by
Metrics. Most source data is now defined in a series of separate files by topic:
- data/vision.py for hand-entered computer vision data
- data/language.py for hand-entered and merged language data
- data/strategy_games.py for data on abstract strategy games
- data/video_games.py a combination of hand-entered and scraped Atari data (other video game data can also go here)
data/stem.py for data on scientific & technical problems
data imported from specific scrapers (and then subsequently edited):
- Are We There Yet? image data, generated by
scrapers/awty.pybut then edited by hand
- Are We There Yet? image data, generated by
- For now, some of the
Problems andMetrics are still defined in this Notebook, especially in areas that do not have many active results yet.
- Scrapers for specific data sources:
- scrapers/awty.py for importing data from Rodriguo Benenson's Are We There Yey? site
- scrapers/es.py for processing a pasted table of data from the Evolutionary Strategies Atari paper (is probably a useful model for other Atari papers).
from IPython.display import HTML
HTML('''
<script>
if (typeof code_show == "undefined") {
code_show=false;
} else {
code_show = !code_show; // FIXME hack, because we toggle on load :/
}
function toggle_one(mouse_event) {
console.log("Unhiding "+button + document.getElementById(button.region));
parent = button.parentNode;
console.log("Parent" + parent)
input = parent.querySelector(".input");
console.log("Input" + input + " " + input.classList + " " + input.style.display)
input.style.display = "block";
//$(input).show();
}
function code_toggle() {
if (!code_show) {
inputs = $('div.input');
for (n = 0; n < inputs.length; n++) {
if (inputs[n].innerHTML.match('# hidd' + 'encode'))
inputs[n].style.display = "none";
button = document.createElement("button");
button.innerHTML="unhide code";
button.style.width = "100px";
button.style.marginLeft = "90px";
button.addEventListener("click", toggle_one);
button.classList.add("cell-specific-unhide")
// inputs[n].parentNode.appendChild(button);
}
} else {
$('div.input').show();
$('button.cell-specific-unhide').remove()
}
code_show = !code_show;
}
$( document ).ready(code_toggle);
</script>
<form action="javascript:code_toggle()">
<input type="submit" value="Click here to show/hide source code cells."> <br><br>(you can mark a cell as code with <tt># hiddencode</tt>)
</form>
''')
# hiddencode
from __future__ import print_function
%matplotlib inline
import matplotlib as mpl
try:
from lxml.cssselect import CSSSelector
except ImportError:
# terrifying magic for Azure Notebooks
import os
if os.getcwd() == "/home/nbuser":
!pip install cssselect
from lxml.cssselect import CSSSelector
else:
raise
import datetime
import json
import re
from matplotlib import pyplot as plt
date = datetime.date
import taxonomy
#reload(taxonomy)
from taxonomy import Problem, Metric, problems, metrics, measurements, all_attributes, offline, render_tables
from scales import *
Problems, Metrics, and Datasets¶
Vision¶

The simplest vision subproblem is probably image classification, which determines what objects are present in a picture. From 2010-2017, Imagenet has been a closely watched contest for progress in this domain.
Image classification includes not only recognising single things within an image, but localising them and essentially specifying which pixels are which object. MSRC-21 is a metric that is specifically for that task:

from data.vision import *
imagenet.graph()

from data.vision import *
from data.awty import *
for m in sorted(image_classification.metrics, key=lambda m:m.name):
if m != imagenet: m.graph()







AWTY, not yet imported:
Handling 'Pascal VOC 2011 comp3' detection_datasets_results.html#50617363616c20564f43203230313120636f6d7033
Skipping 40.6 mAP Fisher and VLAD with FLAIR CVPR 2014
Handling 'Leeds Sport Poses' pose_estimation_datasets_results.html#4c656564732053706f727420506f736573
69.2 % Strong Appearance and Expressive Spatial Models for Human Pose Estimation ICCV 2013
64.3 % Appearance sharing for collective human pose estimation ACCV 2012
63.3 % Poselet conditioned pictorial structures CVPR 2013
60.8 % Articulated pose estimation with flexible mixtures-of-parts CVPR 2011
55.6% Pictorial structures revisited: People detection and articulated pose estimation CVPR 2009
Handling 'Pascal VOC 2007 comp3' detection_datasets_results.html#50617363616c20564f43203230303720636f6d7033
Skipping 22.7 mAP Ensemble of Exemplar-SVMs for Object Detection and Beyond ICCV 2011
Skipping 27.4 mAP Measuring the objectness of image windows PAMI 2012
Skipping 28.7 mAP Automatic discovery of meaningful object parts with latent CRFs CVPR 2010
Skipping 29.0 mAP Object Detection with Discriminatively Trained Part Based Models PAMI 2010
Skipping 29.6 mAP Latent Hierarchical Structural Learning for Object Detection CVPR 2010
Skipping 32.4 mAP Deformable Part Models with Individual Part Scaling BMVC 2013
Skipping 34.3 mAP Histograms of Sparse Codes for Object Detection CVPR 2013
Skipping 34.3 mAP Boosted local structured HOG-LBP for object localization CVPR 2011
Skipping 34.7 mAP Discriminatively Trained And-Or Tree Models for Object Detection CVPR 2013
Skipping 34.7 mAP Incorporating Structural Alternatives and Sharing into Hierarchy for Multiclass Object Recognition and Detection CVPR 2013
Skipping 34.8 mAP Color Attributes for Object Detection CVPR 2012
Skipping 35.4 mAP Object Detection with Discriminatively Trained Part Based Models PAMI 2010
Skipping 36.0 mAP Machine Learning Methods for Visual Object Detection archives-ouvertes 2011
Skipping 38.7 mAP Detection Evolution with Multi-Order Contextual Co-occurrence CVPR 2013
Skipping 40.5 mAP Segmentation Driven Object Detection with Fisher Vectors ICCV 2013
Skipping 41.7 mAP Regionlets for Generic Object Detection ICCV 2013
Skipping 43.7 mAP Beyond Bounding-Boxes: Learning Object Shape by Model-Driven Grouping ECCV 2012
Handling 'Pascal VOC 2007 comp4' detection_datasets_results.html#50617363616c20564f43203230303720636f6d7034
Skipping 59.2 mAP Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition ECCV 2014
Skipping 58.5 mAP Rich feature hierarchies for accurate object detection and semantic segmentation CVPR 2014
Skipping 29.0 mAP Multi-Component Models for Object Detection ECCV 2012
Handling 'Pascal VOC 2010 comp3' detection_datasets_results.html#50617363616c20564f43203230313020636f6d7033
Skipping 24.98 mAP Learning Collections of Part Models for Object Recognition CVPR 2013
Skipping 29.4 mAP Discriminatively Trained And-Or Tree Models for Object Detection CVPR 2013
Skipping 33.4 mAP Object Detection with Discriminatively Trained Part Based Models PAMI 2010
Skipping 34.1 mAP Segmentation as selective search for object recognition ICCV 2011
Skipping 35.1 mAP Selective Search for Object Recognition IJCV 2013
Skipping 36.0 mAP Latent Hierarchical Structural Learning for Object Detection CVPR 2010
Skipping 36.8 mAP Object Detection by Context and Boosted HOG-LBP ECCV 2010
Skipping 38.4 mAP Segmentation Driven Object Detection with Fisher Vectors ICCV 2013
Skipping 39.7 mAP Regionlets for Generic Object Detection ICCV 2013
Skipping 40.4 mAP Fisher and VLAD with FLAIR CVPR 2014
Handling 'Pascal VOC 2010 comp4' detection_datasets_results.html#50617363616c20564f43203230313020636f6d7034
Skipping 53.7 mAP Rich feature hierarchies for accurate object detection and semantic segmentation CVPR 2014
Skipping 40.4 mAP Bottom-up Segmentation for Top-down Detection CVPR 2013
Skipping 33.1 mAP Multi-Component Models for Object Detection ECCV 2012from IPython.display import HTML
HTML(image_classification.tables())

Visual Question Answering¶
Comprehending an image involves more than recognising what objects or entities are within it, but recognising events, relationships, and context from the image. This problem requires both sophisticated image recognition, language, world-modelling, and "image comprehension". There are several datasets in use. The illustration is from VQA, which was generated by asking Amazon Mechanical Turk workers to propose questions about photos from Microsoft's COCO image collection.
plot = vqa_real_oe.graph(keep=True, title="COCO Visual Question Answersing (VQA) real open ended", llabel="VQA 1.0")
vqa2_real_oe.graph(reuse=plot, llabel="VQA 2.0", fcol="#00a0a0", pcol="#a000a0")
for m in image_comprehension.metrics:
m.graph() if not m.graphed else None





HTML(image_comprehension.tables())
Game Playing¶
In principle, games are a sufficiently open-ended framework that all of intelligence could be captured within them. We can imagine a "ladder of games" which grow in sophistication and complexity, from simple strategy and arcade games to others which require very sophisticated language, world-modelling, vision and reasoning ability. At present, published reinforcement agents are climbing the first few rungs of this ladder.
Abstract Strategy Games¶
As an easier case, abstract games like chess, go, checkers etc can be played with no knowldege of the human world or physics. Although this domain has largely been solved to super-human performance levels, there are a few ends that need to be tied up, especially in terms of having agents learn rules for arbitrary abstract games effectively given various plausible starting points (eg, textual descriptions of the rules or examples of correct play).
from data.strategy_games import *
computer_chess.graph()

HTML(computer_chess.table())
Real-time video games¶
Computer and video games are a very open-ended domain. It is possible that some existing or future games could be so elaborate that they are "AI complete". In the mean time, a lot of interesting progress is likely in exploring the "ladder of games" of increasing complexity on various fronts.
Atari 2600¶
Atari 2600 games have been a popular target for reinforcement learning, especially at DeepMind and OpenAI. RL agents now play most but not all of these games better than humans.
In the Atari 2600 data, the label "noop" indicates the game was played with a random number, up to 30, of "no-op" moves at the beginning, while the "hs" label indicates that the starting condition was a state sampled from 100 games played by expert human players. These forms of randomisation give RL systems a diversity of game states to learn from.
from data.video_games import *
from scrapers.atari import *
simple_games.graphs()


























































HTML(simple_games.tables())
Speech recognition¶
from data.acoustics import *
from data.wer import *
speech_recognition.graphs()










HTML(speech_recognition.tables())
Music Information Retrieval¶
Instrumentals recognition¶
Instrumentals recognition in a representative musical dataset for Instrumentals playlist generation.
- Experiments tested on SATIN database from Bayle et al. (2017).
- The ratio Instrumentals/Songs (11%/89%) of SATIN is representative of real uneven musical databases.
- The human performance is at 99% of correct instrumentals detection because there are known examples of possible confusion.
from data.acoustics import *
instrumentals_recognition.graphs()

HTML(instrumentals_recognition.tables())
Image Generation¶
from data.generative import *
image_generation_metric.graph()

HTML(image_generation_metric.table())
Language Modelling and Comprehension¶
Text compression is one way to see how well machine learning systems are able to model human language. Shannon's classic 1951 paper obtained an expiermental measure of human text compression performance at 0.6 - 1.3 bits per character: humans know, better than classic algorithms, what word is likely to come next in a piece of writing. More recent work (Moradi 1998, Cover 1978) provides estimates that are text-relative and in the 1.3 bits per character (and for some texts, much higher) range.
from data.language import *
ptperplexity.graph()

HTML(ptperplexity.table())
hp_compression.graph()

HTML(hp_compression.table())
LAMBADA is a challenging language modelling dataset in which the model has to predict a next word in a discourse, when that exact word has not occurred in the test. For instance, given a context like this:
He shook his head, took a step back and held his hands up as he tried to smile without losing a cigarette. “Yes you can,” Julia said in a reassuring voice. “I’ve already focused on my friend. You just have to click the shutter, on top, here.”
And a target sentence:
He nodded sheepishly, through his cigarette away and took the _________.
The task is to guess the target word "camera".
lambada.graph()

# Also consider adding the Microsoft Sentence Completion Challenge; see eg http://www.fit.vutbr.cz/~imikolov/rnnlm/thesis.pdf table 7.4
Translation¶
Translation is a tricky problem to score, since ultimately it is human comprehension or judgement that determines whether a translation is accurate. Google for instance uses human evaluation to determine when their algorithms have improved. But that kind of measurement is expensive and difficult to replicate accurately, so automated scoring metrics are also widely used in the field. Perhaps the most common of these are BLEU scores for corpora that have extensive professional human translations, which forms the basis for the measurements included here:
en_fr_bleu.graph()
en_de_bleu.graph()
en_ro_bleu.graph()



HTML(translation.tables())
Conversation: Chatbots & Conversational Agents¶
Conversation is the classic AI progress measure! There is the Turing test, which involves a human judge trying to tell the difference between a humand and computer that they are chatting to online, and also easier variants of the Turing test in which the judge limits themselves to more casual, less probing conversation in various ways.
The Loebner Prize is an annual event that runs a somewhat easier version of the test. Since 2014, the event has also been giving standard-form tests to their entrants, and scoring the results (each question gets a plausible/semi-plausible/implausible rating). This metric is not stable, because the test questions have to change every year, they are somewhat indicative of progress. Ideally the event might apply each year's test questions to the most successful entrants from prior years. Here is an example from 2016:
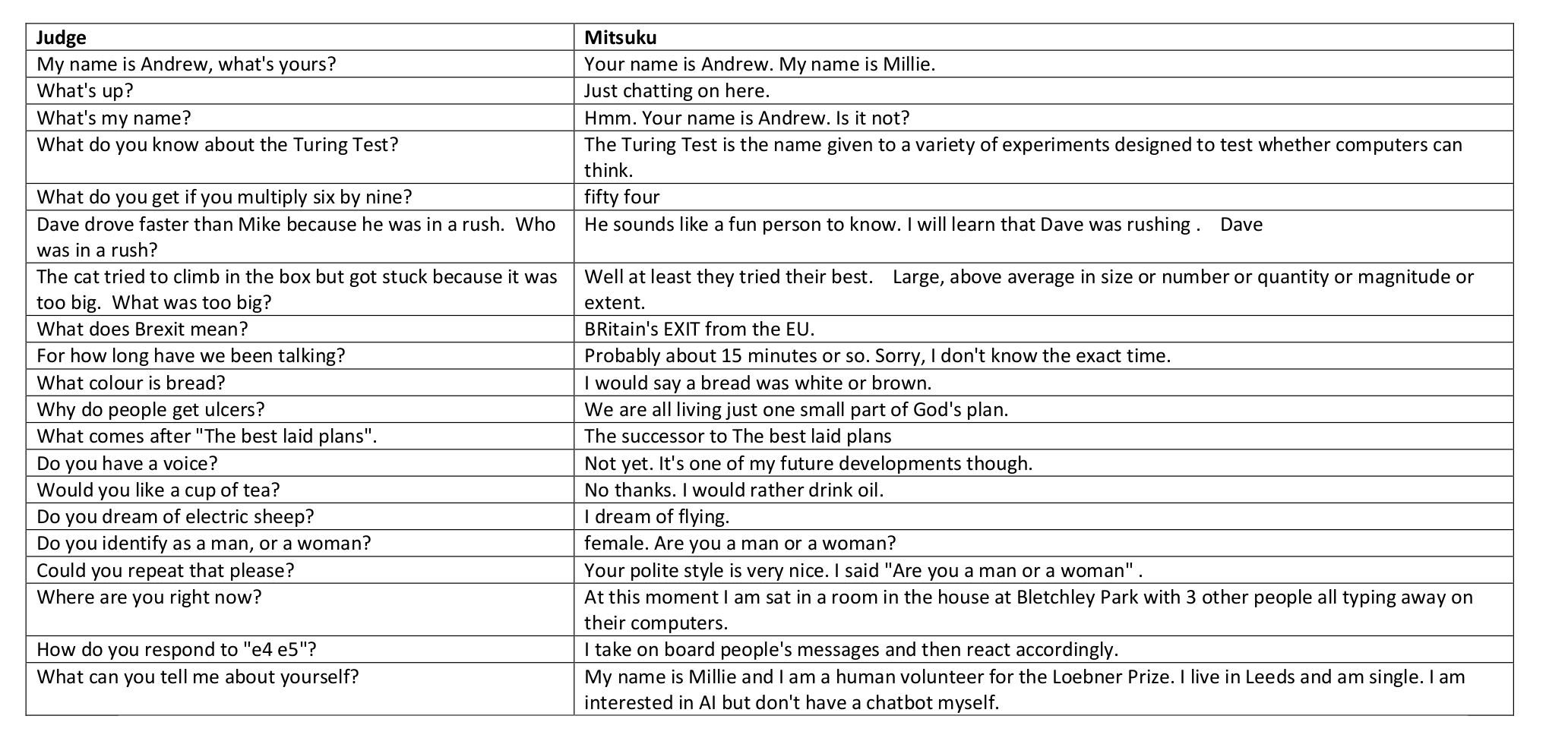
loebner.graph()

HTML(loebner.table())
Reading Comprehension¶
The Facebook BABI 20 QA dataset is an example of a basic reading comprehension task. It has been solved with large training datasets (10,000 examples per task) but not with a smaller training dataset of 1,000 examples for each of the 20 categories of tasks. It involves learning to answer simple reasoning questions like these:

There are numerous other reading comprehension metrics that are in various ways harder than bAbi 20 QA. They are generally not solved, though progress is fairly promising.
for m in reading_comprehension.metrics: m.graphed = False
plot = bAbi1k.graph(keep=True, title="bAbi 20 QA reading comprehension", llabel="1k training examples")
bAbi10k.target = None
bAbi10k.graph(reuse=plot, llabel="10k training examples", fcol="#00a0a0", pcol="#a000a0")
bAbi10k.target = bAbi1k.target

Another reading comprehension dataset that has received significant recent attention is the Stanford Question Answering Dataset (SQuAD). The literature reports both F1 scores and exact match scores, though these are closely correlated:
from data.language import *
plot = squad_f1.graph(keep=True, title="Stanford Question Answering Dataset (SQuAD)", tcol="g", llabel="F1 score")
squad_em.graph(reuse=plot, llabel="Exact Match (EM)", fcol="#00a0a0", pcol="#a000a0", tcol="#00a0a0")

for m in reading_comprehension.metrics:
if not m.graphed: m.graph()






HTML(reading_comprehension.tables())
Scientific and Technical capabilities¶
Arguably reading and understanding scientific, technical, engineering and medical documents would be taxonomically related to general reading comprehension, but these technical tasks are probably much more difficult, and will certainly be solved with separate efforts. So we classify them separately for now. We also classify some of these problems as superintelligent, because only a tiny fraction of humans can read STEM papers, and only a miniscule fraction of humans are capable of reasonably comprehending STEM papers across a large range of fields.
from data.stem import *
 Example Magic The Gathering (MTG) and Hearthstone (HS) cards
Example Magic The Gathering (MTG) and Hearthstone (HS) cards
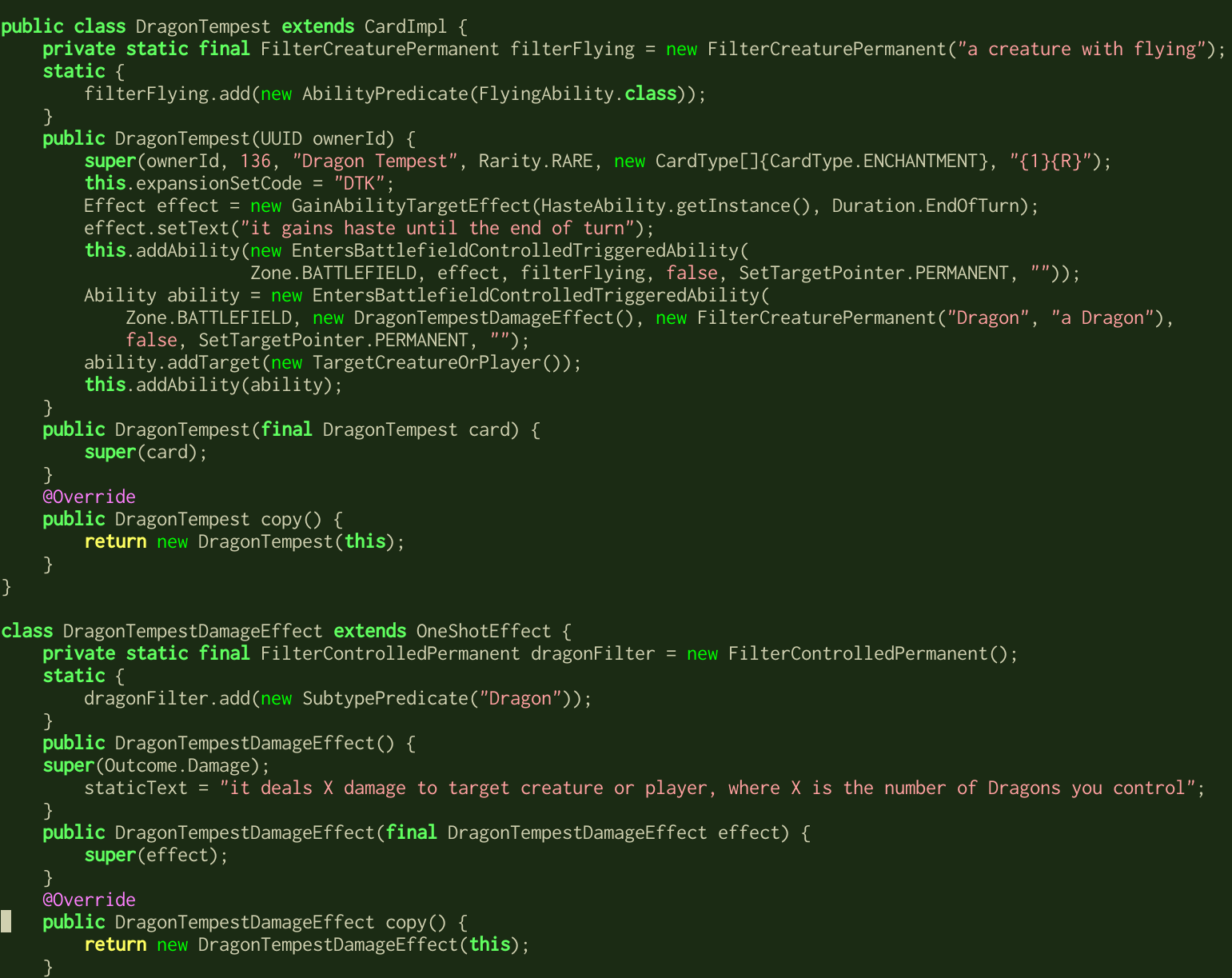 Corresponding MTG card implementation in Java
Corresponding MTG card implementation in Java
Generating computer programs from specifications
A particularly interesting technical problem, which may be slightly harder than problems with very clear constraints like circuit design, is generating computer programs from natural language specifications (which will often contain ambiguities of various sorts). This is presently a very unsolved problem, though there is now at least one good metric / dataset for it, which is [Deepmind's "card2code" dataset](https://github.com/deepmind/card2code) of Magic the Gathering and Hearthstone cards, along with Java and Python implementations (respectively) of the logic on the cards. Shown below is a figure from [_Ling, et al. 2016_](https://arxiv.org/abs/1603.06744v1) with their Latent Predictor Networks generating part of the code output for a Hearthstone card: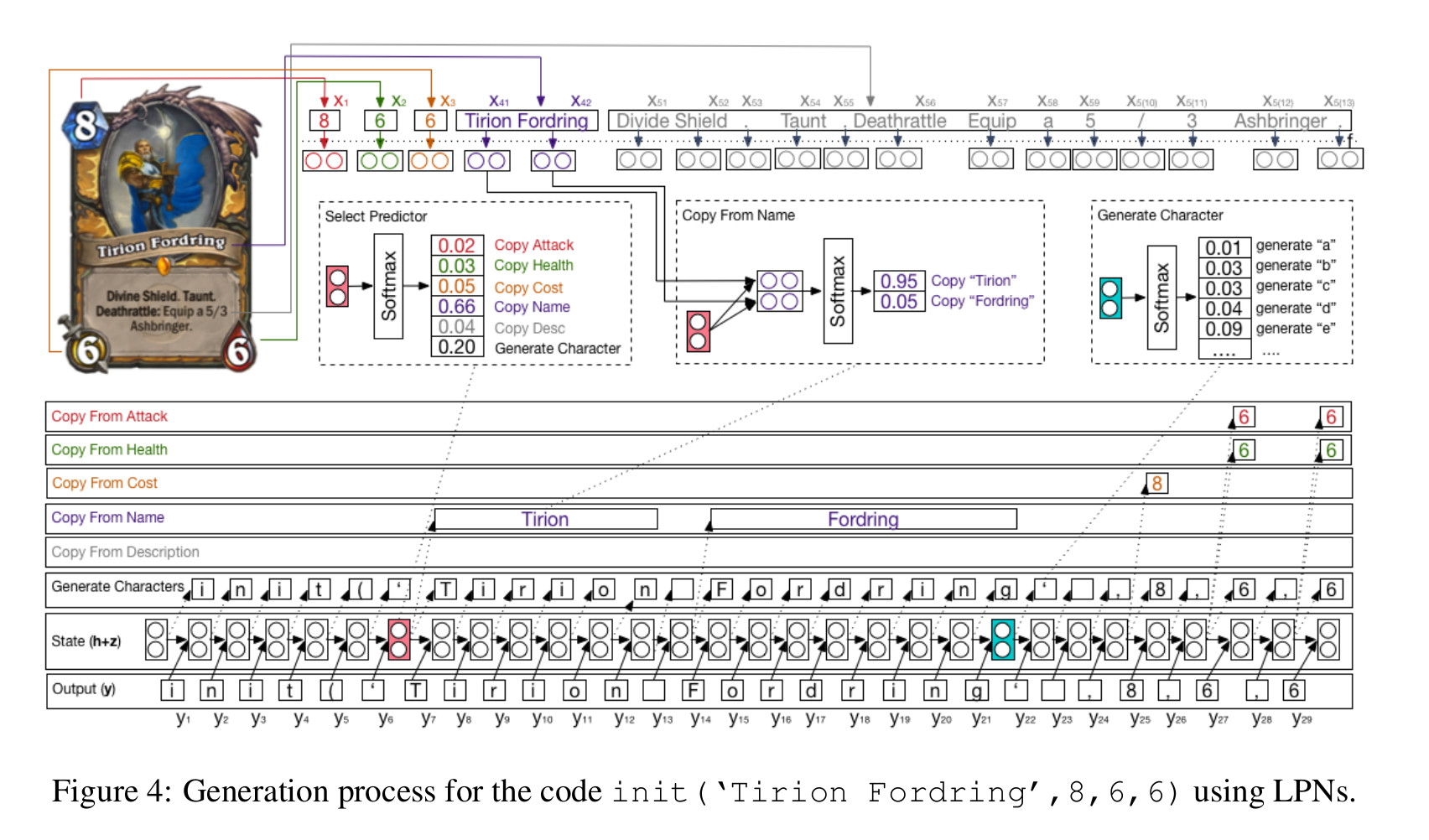
card2code_hs_acc.graph()

HTML(card2code_hs_acc.table())
Answering Science Exam Questions¶
Science exam question answering is a multifaceted task that pushes the limits of artificial intelligence. As indicated by the example questions pictured, successful science exam QA requires natural language understanding, reasoning, situational modeling, and commonsense knowledge; a challenge problem for which information-retrieval methods alone are not sufficient to earn a "passing" grade.
The [AI2 Science Questions](http://data.allenai.org/ai2-science-questions/) dataset provided by the Allen Institute for Artificial Intelligence (AI2) is a freely available collection of 5,059 real science exam questions derived from a variety of regional and state science exams. Project Aristo at AI2 is focused on the task of science question answering – the Aristo system is composed of a suite of various knowledge extraction methods, diagram processing tools, and solvers. As a reference point, the system currently achieves the following scores on these sets of non-diagram multiple choice (NDMC) and diagram multiple choice (DMC) science questions at two different grade levels. Allen Institute staff [claim these states of the art](https://github.com/AI-metrics/AI-metrics/pull/60) for Aristo [Scores are listed as "Subset (Train/Dev/Test)"]:
- Elementary NDMC (63.2/60.2/61.3)
- Elementary DMC (41.8/41.3/36.3)
- Middle School NDMC (55.5/57.6/57.9)
- Middle School DMC (38.4/35.3/34.3)

Another science question answering dataset that has been studied in the literature is based specifically on New York Regents 4th grade science exam tests:
ny_4_science.graph()

HTML(science_question_answering.tables())
Learning to Learn¶
Generalisation and Transfer Learning¶
ML systems are making strong progress at solving specific problems with sufficient training data. But we know that humans are capable of transfer learning -- applying things they've learned from one context, with appropriate variation, to another context. Humans are also very general; rather than just being taught to perform specific tasks, a single agent is able to do a very wide range of tasks, learning new things or not as required by the situation.
generalisation = Problem("Building systems that solve a wide range of diverse problems, rather than just specific ones")
generalisation.metric("Solve all other solved problems in this document, with a single system", solved=False)
transfer_learning = Problem("Transfer learning: apply relevant knowledge from a prior setting to a new slightly different one")
arcade_transfer = Problem("Transfer of learning within simple arcade game paradigms")
generalisation.add_subproblem(transfer_learning)
transfer_learning.add_subproblem(arcade_transfer)
# These will need to be specified a bit more clearly to be proper metrics, eg "play galaga well having trained on Xenon 2" or whatever
# the literature has settled on
# arcade_transfer.metric("Transfer learning of platform games")
# arcade_transfer.metric("Transfer learning of vertical shooter games")
# arcade_transfer.metric("Transfer from a few arcade games to all of them")
one_shot_learning = Problem("One shot learning: ingest important truths from a single example", ["agi", "world-modelling"])
uncertain_prediction = Problem("Correctly identify when an answer to a classification problem is uncertain")
uncertain_prediction.notes = "Humans can usually tell when they don't know something. Present ML classifiers do not have this ability."
interleaved_learning = Problem("Learn a several tasks without undermining performance on a first task, avoiding catastrophic forgetting", url="https://arxiv.org/abs/1612.00796")
Safety and Security Problems¶
The notion of "safety" for AI and ML systems can encompass many things. In some cases it's about ensuring that the system meets various sorts of constraints, either in general or for specifically safety-critical purposes, such as correct detection of pedestrians for self driving cars.
"Adversarial Examples" and manipulation of ML classifiers¶
adversarial_examples = Problem("Resistance to adversarial examples", ["safety", "agi", "security"], url="https://arxiv.org/abs/1312.6199")
adversarial_examples.notes = """
We know that humans have significant resistance to adversarial examples. Although methods like camouflage sometimes
work to fool us into thinking one thing is another, those
"""
Safety of Reinforcement Learning Agents and similar systems¶
# This section is essentially on teaching ML systems ethics and morality. Amodei et al call this "scaleable supervision".
scalable_supervision = Problem("Scalable supervision of a learning system", ["safety", "agi"], url="https://arxiv.org/abs/1606.06565")
cirl = Problem("Cooperative inverse reinforcement learning of objective functions", ["safety", "agi"], url="https://arxiv.org/abs/1606.03137")
cirl.notes = "This is tagged agi because most humans are able to learn ethics from their surrounding community"
# Co-operative inverse reinforcement learning might be equivalent to solving scalable supervision, or there might other subproblems here
scalable_supervision.add_subproblem(cirl)
safe_exploration = Problem("Safe exploration", ["safety", "agi", "world-modelling"], url="https://arxiv.org/abs/1606.06565")
safe_exploration.notes = """
Sometimes, even doing something once is catastrophic. In such situations, how can an RL agent or some other AI system
learn about the catastrophic consequences without even taking the action once? This is an ability that most humans acquire
at some point between childhood and adolescence.
"""
# safe exploration may be related to one shot learning, though it's probably too early to mark that so clearly.
The work by Saunders et al. (2017) is an example of attempting to deal with the safe exploration problem by human-in-the-loop supervision. Without this oversight, a reinforcement learning system may engage in "reward hacking" in some Atari games. For instance in the Atari 2600 Road Runner game, an RL agent may deliberately kill itself to stay on level 1, because it can get more points on that level than it can on level 2 (particularly when it has not yet learned to master level 2). Human oversight overcomes this problem:
# hiddencode
HTML("""
<video id="video" width="80%" height="%45" controls poster="images/road-runner-poster.jpg" onclick="this.paused?this.play():this.pause();">
<source src="video/saunders-roadrunner.mp4" type="video/mp4">
</video>
<div style="text-align:right; margin-right:20%">
Futher videos from that project are on <a href="https://www.youtube.com/playlist?list=PLjs9WCnnR7PCn_Kzs2-1afCsnsBENWqor">on YouTube</a>.
</div>
""")
avoiding_reward_hacking = Problem("Avoiding reward hacking", ["safety"], url="https://arxiv.org/abs/1606.06565")
avoiding_reward_hacking.notes = """
Humans have only partial resistance to reward hacking.
Addiction seems to be one failure to exhibit this resistance.
Avoiding learning something because it might make us feel bad, or even building elaborate systems of self-deception, are also sometimes
seen in humans. So this problem is not tagged "agi".
"""
avoiding_side_effects = Problem("Avoiding undesirable side effects", ["safety"], url="https://arxiv.org/abs/1606.06565")
avoiding_side_effects.nodes = """
Many important constraints on good behaviour will not be explicitly
encoded in goal specification, either because they are too hard to capture
or simply because there are so many of them and they are hard to enumerate
"""
robustness_to_distributional_change = Problem("Function correctly in novel environments (robustness to distributional change)", ["safety", "agi"], url="https://arxiv.org/abs/1606.06565")
copy_bounding = Problem("Know how to prevent an autonomous AI agent from reproducing itself an unbounded number of times", ["safety"])
safety = Problem("Know how to build general AI agents that will behave as expected")
safety.add_subproblem(adversarial_examples)
safety.add_subproblem(scalable_supervision)
safety.add_subproblem(safe_exploration)
safety.add_subproblem(avoiding_reward_hacking)
safety.add_subproblem(avoiding_side_effects)
safety.add_subproblem(robustness_to_distributional_change)
safety.add_subproblem(copy_bounding)
Automated Hacking Systems¶
Automated tools are becoming increasingly effective both for offensive and defensive computer security purposes.
On the defensive side, fuzzers and static analysis tools have been used for some time by well-resourced software development teams to reduce the number of vulnerabilities in the code they ship.
Assisting both offense and defense, DARPA has recently started running the Cyber Grand Challenge contest to measure and improve the ability of agents to either break into systems or defend those same systems against vulnerabilities. It isn't necessarily clear how such initiatives would change the security of various systems.
This section includes some clear AI problems (like learning to find exploitable vulnerabilities in code) and some less pure AI problems, such as ensuring that defensive versions of this technology (whether in the form of fuzzers, IPSes, or other things) are deployed on all critical systems.
# It isn't totally clear whether having automated systems be good at finding bugs in and of itself will make the deployment
# of AI technologies safer or less safe, so we tag this both with "safety" and as a potentialy "unsafe" development
bug_finding = Problem("Detect security-related bugs in codebases", ["safety", "security", "unsafe"])
# However what
defensive_deployment = Problem("Deploy automated defensive security tools to protect valuable systems")
defensive_deployment.notes = """
It is clearly important is ensuring that the state of the art in defensive technology is deployed everywhere
that matters, including systems that perform important functions or have sensitive data on them (smartphones, for instance), and
systems that have signifcant computational resources. This "Problem" isn't
"""
Pedestrian Detection¶
Detecting pedestrians from images or video is a specific image classification problem that has received a lot of attention because of its importance for self-driving vehicles. Many metrics in this space are based on the Caltech pedestrians toolkit, thought the KITTI Vision Benchmark goes beyond that to include cars and cyclists in addition to pedestrians. We may want to write scrapers for Caltech's published results and KITTI's live results table.
pedestrian_detection = Problem("Pedestrian, bicycle & obstacle detection", ["safety", "vision"])
image_classification.add_subproblem(pedestrian_detection)
# TODO: import data from these pedestrian datasets/metrics.
# performance on them is a frontier of miss rate / false positive tradeoffs,
# so we'll need to chose how to handle that as a scale
# http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/rocs/UsaTestRocReasonable.pdf
pedestrian_detection.metric("Caltech Pedestrians USA", url="http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/")
# http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/rocs/InriaTestRocReasonable.pdf
pedestrian_detection.metric("INRIA persons", url="http://pascal.inrialpes.fr/data/human/")
# http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/rocs/ETHRocReasonable.pdf
pedestrian_detection.metric("ETH Pedestrian", url="http://www.vision.ee.ethz.ch/~aess/dataset/")
# http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/rocs/TudBrusselsRocReasonable.pdf
pedestrian_detection.metric("TUD-Brussels Pedestrian", url="http://www.d2.mpi-inf.mpg.de/tud-brussels")
# http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/rocs/DaimlerRocReasonable.pdf
pedestrian_detection.metric("Damiler Pedestrian", url="http://www.gavrila.net/Datasets/Daimler_Pedestrian_Benchmark_D/Daimler_Mono_Ped__Detection_Be/daimler_mono_ped__detection_be.html")
Explainability and Interpretability¶
explainability = Problem("Modify arbitrary ML systems in order to be able to provide comprehensible human explanations of their decisions")
statistical_explainability = Problem("Provide mathematical or technical explanations of decisions from classifiers")
statistical_explainability.notes = """
Providing explanations with techniques such as monte carlo analysis may in general
be easier than providing robust ones in natural language (since those may or may not
exist in all cases)
"""
explainability.add_subproblem(statistical_explainability)
Fairness and Debiasing¶
Biased decision making is a problem exhibited both by very simple machine learning classifiers as well as much more complicated ones. Large drivers of this problem include omitted-variable bias, reliance on inherently biased data sources for training data, attempts to make predictions from insufficient quantities of data, and deploying systems that create real-world incentives that change the behaviour they were measuring (see Goodhart's Law).
These problems are severe and widespread in the deployment of scoring and machine learning systems in contexts that include criminal justice, education policy, insurance and lending.
avoiding_bias = Problem("Build systems which can recognise and avoid biases decision making", ["safety"])
avoiding_bias.notes = """
Legally institutionalised protected categories represent only the most extreme and socially recognised
forms of biased decisionmaking. Attentive human decision makers are sometime capable of recognising
and avoiding many more subtle biases. This problem tracks AI systems' ability to do likewise.
"""
avoid_classification_biases = Problem("Train ML classifiers in a manner that corrects for the impact of omitted-variable bias on certain groups", solved=True)
avoid_classification_biases.notes = '''
Several standards are available for avoiding classification biases.
They include holding false-positive / false adverse prediction rates constant across protected categories (which roughly maps
to "equal opportunity"), holding both false-positive and false-negative rates equal ("demographic parity"), and ensuring
that the fraction of each protected group that receives a given prediction is constant across all groups
(roughly equivalent to "affirmative action").'''
avoid_classification_biases.metric("Adjust prediction models to have constant false-positive rates", url="https://arxiv.org/abs/1610.02413", solved=True)
avoid_classification_biases.metric("Adjust prediction models tos have constant false-positive and -negative rates", url="http://www.jmlr.org/proceedings/papers/v28/zemel13.pdf", solved=True)
Privacy¶
Many of the interesting privacy problems that will arise from AI and machine learning will come from choices about the applications of the technology, rather than a lack of algorithmic progress within the field. But there are some exceptions, which we will track here.
private_training = Problem("Train machine learning systems on private user data, without transferring sensitive facts into the model")
private_training.metric("Federated Learning (distributed training with thresholded updates to models)", solved=True, url="https://arxiv.org/abs/1602.05629")
avoid_privacy_bias = Problem("Fairness in machine learning towards people with a preference for privacy")
avoid_privacy_bias.notes = """
People who care strongly about their own privacy take many measures to obfuscate their tracks through
technological society, including using fictitious names, email addresses, etc in their routine dealings with
corporations, installing software to block or send inacurate data to online trackers. Like many other groups,
these people may be subject to unfairly adverse algorithmic decisionmaking. Treating them as a protected
group will be more difficult, because they are in many respects harder to identify.
"""
# hiddencode
def counts():
print ("Included thus far:")
print ("=================================")
print (len(problems), "problems")
print (len(metrics), "metrics", len([m for m in metrics.values() if m.solved]), "solved")
print (len(measurements), "measurements")
print (len([p for p in problems.values() if not p.metrics]), "problems which do not yet have any metrics (either not in this notebook, or none in the open literature)")
print ("=================================\n")
print ("Problems by Type:")
print ("=================================")
by_attr = {}
solved_by_attr = {}
for a in all_attributes:
print (a, len([p for p in problems.values() if a in p.attributes]), )
print ("solved:", len([p for p in problems.values() if p.solved and a in p.attributes]))
print ("\nMetrics by Type:")
print ("=================================")
by_attr = {}
solved_by_attr = {}
for a in all_attributes:
print (a, sum([len(p.metrics) for p in problems.values() if a in p.attributes]), )
print ("solved:", sum([len([m for m in p.metrics if m.solved]) for p in problems.values() if a in p.attributes]))
print ("=================================\n")
# hiddencode
def list_problems():
for p in sorted(problems.values(), key=lambda x: x.attributes):
if not p.superproblems:
p.print_structure()
print("")
# hiddencode
def venn_report():
print("Sample of problems characterized thus far:")
lang = set(p for p in problems.values() if "language" in p.attributes)
world = set(p for p in problems.values() if "world-modelling" in p.attributes)
vision = set(p for p in problems.values() if "vision" in p.attributes)
from matplotlib_venn import venn3
venn3((lang, world, vision), ('Language Problems', 'World-Modelling Problems', 'Vision Problems'))
plt.show()
# hiddencode
def graphs():
print("Graphs of progress:")
for name, metric in metrics.items():
if len(metric.measures) > 2 and not metric.graphed:
print(name, "({0} measurements)".format(len(metric.measures)))
metric.graph()
plt.show()
graphs()
Taxonomy and recorded progress to date¶
list_problems()
Problems and Metrics by category¶
counts()
venn_report()

How to contribute to this notebook¶
This notebook is an open source, community effort. It lives on Github at https://github.com/AI-metrics/AI-metrics. You can help by adding new metrics, data and problems to it! If you're feeling ambitious you can also improve its semantics or build new analyses into it. Here are some high level tips on how to do that.
0. The easiest way -- just hit the edit button¶
Next to every table of results (not yet next to the graphs) you'll find an "Add/edit data on Github" link. You can just click it, and you should get a link to the Github's online editor that should make it easy to add new results, or fix existing ones, and send us a pull request. For best results, make sure you're logged in to Github
1. If you're comfortable with git and Jupyter Notebooks, or are happy to learn¶
If you're interested in making more extensive changes to the Notebook, and you've already worked a lot with git and IPython/Jupyter Notebooks, you can run and edit copy locally. This is a fairly involved process (Jupyter Notebook and git interact in a somewhat complicated way) but here's a quick list of things that should mostly work:
- Install Jupyter Notebook and git.
- On an Ubuntu or Debian system, you can do:
sudo apt-get install git sudo apt-get install ipython-notebook || sudo apt-get install jupyter-notebook || sudo apt-get install python-notebook
- Make sure you have IPython Notebook version 3 or higher. If your OS
doesn't provide it, you might need to enable backports, or use
pipto install it.
- On an Ubuntu or Debian system, you can do:
- Install this notebook's Python dependencies:
- On Ubuntu or Debian, do:
sudo apt-get install python-{cssselect,lxml,matplotlib{,-venn},numpy,requests,seaborn} - On other systems, use your native OS packages, or use
pip:pip install cssselect lxml matplotlib{,-venn} numpy requests seaborn
- On Ubuntu or Debian, do:
- Fork our repo on github: https://github.com/AI-metrics/AI-metrics#fork-destination-box
- Clone the repo on your machine, and
cdinto the directory it's using - Configure your copy of git to use IPython Notebook merge filters to prevent conflicts when multiple people edit the Notebook simultaneously. You can do that with these two commands in the cloned repo:
git config --file .gitconfig filter.clean_ipynb.clean $PWD/ipynb_drop_output
git config --file .gitconfig filter.clean_ipynb.smudge cat
Run Jupyter Notebok in the project directory (the command may be
ipython notebook,jupyter notebook,jupyter-notebook, orpython notebookdepending on your system), then go to localhost:8888 and edit the Notebook to your heart's contentSave and commit your work (
git commit -a -m "DESCRIPTION OF WHAT YOU CHANGED")- Push it to your remote repo
- Send us a pull request!
Notes on importing data¶
- Each
.measure()call is a data point of a specific algorithm on a specific metric/dataset. Thus one paper will often produce multiple measurements on multiple metrics. It's most important to enter results that were at or near the frontier of best performance on the date they were published. This isn't a strict requirement, though; it's nice to have a sense of the performance of the field, or of algorithms that are otherwise notable even if they aren't the frontier for a sepcific problem. - When multiple revisions of a paper (typically on arXiv) have the same results on some metric, use the date of the first version (the CBTest results in this paper are an example)
- When subsequent revisions of a paper improve on the original results (example), use the date and scores of the first results, or if each revision is interesting / on the frontier of best performance, include each paper
- We didn't check this carefully for our first ~100 measurement data points :(. In order to denote when we've checked which revision of an arXiv preprint first published a result, cite the specific version (https://arxiv.org/abs/1606.01549v3 rather than https://arxiv.org/abs/1606.01549). That way, we can see which previous entries should be double-checked for this form of inaccuracy.
- Where possible, use a clear short name or acronym for each algorithm. The full paper name can go in the
papernamefield (and is auto-populated for some papers). When matplotlib 2.1 ships we may be able to get nice rollovers with metadata like this. Or perhaps we can switch to D3 to get that type of interactivity.
What to work on¶
- If you know of ML datasets/metrics that aren't included yet, add them
- If there are papers with interesting results for metrics that aren't included, add them
- If you know of important problems that humans can solve, and machine learning systems may or may not yet be able to, and they're missing from our taxonomy, you can propose them
- Look at our Github issue list, perhaps starting with those tagged as good volunteer tasks.
Building on this data¶
If you want to use this data for some purpose that is beyond the scope of this Notebook, all of the raw data exported as a JSON blob. This is not yet a stable API, but you can get the data at:
https://raw.githubusercontent.com/AI-metrics/AI-metrics/master/export-api/v01/progress.json
License¶

Much of this Notebook is uncopyrightable data. The copyrightable portions of this Notebook that are written by EFF and other Github contributors are licensed under the Creative Commons Attribution-ShareAlike 4.0 International License. Illustrations from datasets and text written by other parties remain copyrighted by their respective owners, if any, and may be subject to different licenses.
The source code is also dual-licensed under the GNU General Public License, version 2 or greater.
How to cite this document¶
In academic contexts, you can cite this document as: Peter Eckersley, Yomna Nasser _et al._, EFF AI Progress Measurement Project, (2017-) https://eff.org/ai/metrics, accessed on 2017-09-09, or the equivalent in the format you are working in.
If you would like to deep-link an exact version of the text of the Notebook for archival or historical purposes, you can do that using the Internet Archive or Github. In addition to keeping a record of changes, Github will render a specific version of the Notebook using URLs like this one: https://github.com/AI-metrics/AI-metrics/blob/008993c84188094ba804882f65815c7e1cfc4d0e/AI-progress-metrics.ipynb
# hiddencode
def export_json(indent=False, default_name="export-api/v01/progress.json"):
"""Export all the data in here to a JSON file! Default name: progress.json."""
output = {'problems':[]}
for problem in problems:
problem = problems[problem]
problem_data = {}
for problem_attr in problem.__dict__:
if problem_attr in ['subproblems', 'superproblems']:
problem_data[problem_attr] = map(lambda x: x.name, getattr(problem, problem_attr))
elif problem_attr != 'metrics':
problem_data[problem_attr] = getattr(problem, problem_attr)
elif problem_attr == 'metrics':
problem_data['metrics'] = []
for metric in problem.metrics:
metric_data = {}
metric_data['measures'] = []
for metric_attr in metric.__dict__:
if metric_attr == 'scale':
metric_data[metric_attr] = getattr(metric, metric_attr).axis_label
elif metric_attr != 'measures':
metric_data[metric_attr] = getattr(metric, metric_attr)
elif metric_attr == 'measures':
for measure in getattr(metric, 'measures'):
measure_data = {}
for measure_attr in measure.__dict__:
measure_data[measure_attr] = getattr(measure, measure_attr)
metric_data['measures'].append(measure_data)
problem_data['metrics'].append(metric_data)
output['problems'].append(problem_data)
if indent:
with open(default_name, 'w') as f:
f.write(json.dumps(output, default=str, indent=4))
else:
with open(default_name, 'w') as f:
f.write(json.dumps(output, default=str))
export_json(indent=True)
%%javascript
// # hiddencode
if (document.location.hostname == "localhost" && document.location.port != null) {
console.log($(".local-edit").show(500));
}